- 1. Обучение с учителем
- 2. Обучение без учителя
- 3. Обучение с частичным привлечением учителя
- 4. Обучение с подкреплением
- 5. Наиболее часто используемые алгоритмы машинного обучения
- 6. Линейная регрессия и линейный классификатор
- 7. Логистическая регрессия
- 8. Деревья принятия решений
- 9. Метод k-средних
- 10. Анализ основных компонентов
- 11. Нейронные сети
- 12. Заключение
- 13. Рекомендуемая литература
Многие статьи об алгоритмах машинного обучения предоставляют отличные определения - но они не облегчают выбор алгоритма, который вам следует использовать. Прочтите эту статью!
Когда я начинал свое путешествие по науке о данных, я часто сталкивался с проблемой выбора наиболее подходящего алгоритма для моей конкретной задачи. Если вы похожи на меня, то, когда вы открываете статью об алгоритмах машинного обучения, вы видите сотни подробных описаний. Парадокс заключается в том, что это не облегчает выбор того, какой из них использовать.
В этой статье для Statsbot я постараюсь объяснить основные понятия и дать некоторую интуицию использования различных видов алгоритмов машинного обучения для различных задач. В конце статьи вы найдете структурированный обзор основных особенностей описываемых алгоритмов.
Прежде всего, следует выделить четыре типа задач машинного обучения:
- Обучение с учителем
- Обучение без учителя
- Обучение с частичным привлечениям учителя
- Обучение с подкреплением
Обучение с учителем
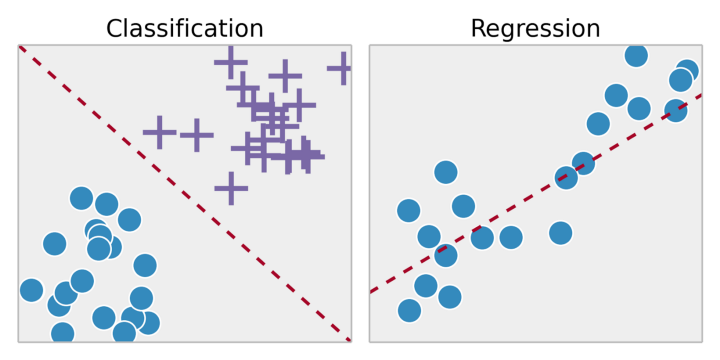
Обучение с учителем является задачей обучения системы на тренировочном наборе данных. Путем подгонки результатов обучения к тренировочному набору данных, мы хотим найти наиболее оптимальные параметры модели для прогнозирования возможных ответов на других объектах (тестовых наборах данных). Если множество возможных ответов является действительным числом, то это задача регрессии. Если множество возможных ответов имеет ограниченное количество значений, где эти значения являются неупорядоченными, то это задача классификации.
Обучение без учителя
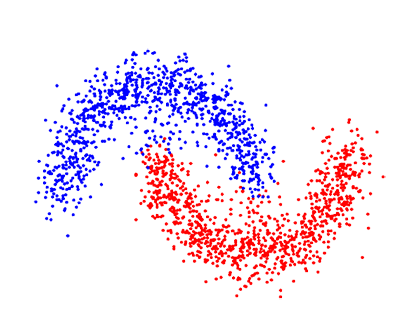
В неконтролируемом обучении у нас меньше информации об объектах. В частности, тренировочный набор данных не имеет маркированных данных, относящихся к определённому классу заранее предопределённых данных. Какова наша цель сейчас? Возможно, наблюдать некоторое сходство между группами объектов и включать их в соответствующие кластеры. Некоторые объекты могут сильно отличаться от всех кластеров, и таким образом мы предполагаем, что эти объекты являются аномалиями.
Обучение с частичным привлечением учителя
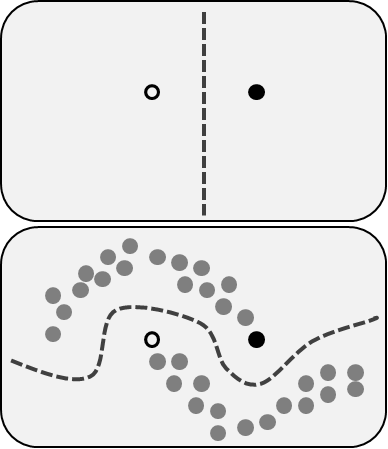
Обучение с частичным привлечением учителя включает обе проблемы, которые мы описали ранее: они используют маркированные, предопределённые и непредопределённые, немаркированные данные. Это отличная возможность для тех, кто не может редопределить, маркировать свои данные. Этот метод позволяет значительно повысить точность, поскольку мы можем использовать непредопределённые данные в тренировочном наборе данных с небольшим количеством маркированных предопределённых данных.
Обучение с подкреплением
Обучение с подкреплением не похоже ни на любую из наших предыдущих задач, потому что здесь мы не располагаем ни предопределёнными маркированными данными, ни немаркированными наборами данных. Обучение с подкреплением - область машинного обучения, связанная с тем, как агенты программного обеспечения должны предпринимать действия в некоторой среде, чтобы максимизировать некоторое понятие кумулятивной награды.
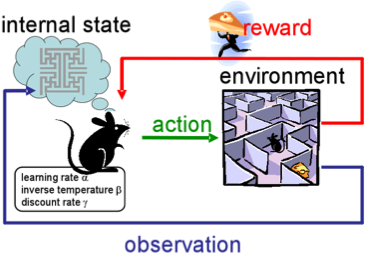
Представьте, что вы робот в каком-то странном месте. Вы можете выполнять действия и получать награды от окружающей среды для них. После каждого действия ваше поведение становится более сложным и умным, поэтому вы тренируетесь, чтобы вести себя наиболее эффективным способом на каждом шаге. В биологии это называется адаптацией к природной среде.
Наиболее часто используемые алгоритмы машинного обучения
Теперь, когда мы знакомы с типами задач машинного обучения, давайте рассмотрим самые популярные алгоритмы с их применением в реальной жизни.
Линейная регрессия и линейный классификатор
Вероятно, это самые простые алгоритмы машинного обучения. У вас есть функции x1, ... xn объектов (матрица A) и метки (вектор b). Ваша цель - найти наиболее оптимальные веса w1, ... wn и смещение для этих функций в соответствии с некоторой функцией потерь; например, среднеквадратичная ошибка или средняя абсолютная ошибка для задачи регрессии. В случае среднеквадратичной ошибки существует математическое уравнение из метода наименьших квадратов:
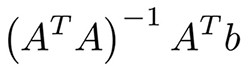
На практике легче оптимизировать его с помощью градиентного спуска, что намного более эффективно вычисляется. Несмотря на простоту этого алгоритма, он работает очень хорошо, когда у вас есть тысячи функций; например, набор слов или n-граммов при анализе текста. Более сложные алгоритмы страдают от переназначения многих функций, а не огромных наборов данных, в то время как линейная регрессия обеспечивает достойное качество.

Чтобы предотвратить переобучение, мы часто используем методы регуляризации, такие как лассо и гребень. Идея состоит в том, чтобы добавить сумму модулей весов и сумму квадратов весов, соответственно, к нашей функции потерь. Прочтите большой учебник по этим алгоритмам в конце статьи.
Логистическая регрессия
Не путайте эти алгоритмы классификации с методами регрессии из-за использования «регрессии» в названии. Логистическая регрессия выполняет двоичную классификацию, поэтому маркированные выходы являются двоичными. Определим P (y = 1 | x) как условную вероятность того, что выход y равен 1 при условии, что задан входной вектор-функция x. Коэффициенты w - это веса, которые модель хочет изучить.
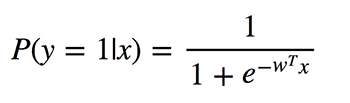
Поскольку этот алгоритм вычисляет вероятность принадлежности к каждому классу, вы должны учитывать, насколько вероятность отличается от 0 или 1 и усредняет его по всем объектам, как это было с линейной регрессией. Такая функция потерь представляет собой среднее значение кросс-энтропии:
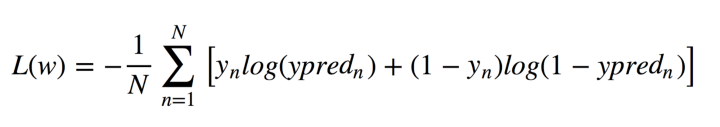
Не паникуйте! Я облегчу это для вас. Позвольте y иметь правильные ответы: 0 или 1, y_pred - предсказанные ответы. Если y равно 0, то первое слагаемое при сумме равно 0, а второе меньше, чем мы предсказали y_pred до 0 согласно свойствам логарифма. Аналогично, в случае, когда y равно 1.
Что хорошего в логистической регрессии? Он принимает линейную комбинацию функций и применяет к ней нелинейную функцию (сигмовидную), поэтому это очень маленький экземпляр нейронной сети!
Деревья принятия решений
Другой популярный и простой в понимании алгоритм - это деревья решений. Их графика поможет вам понять, что вы думаете, и их движок требует систематического документированного процесса мышления.
Идея этого алгоритма довольно проста. В каждом узле мы выбираем лучший вариант между всеми функциями и всеми возможными точками разделения. Каждый вариант выбирается таким образом, чтобы максимизировать некоторый функционал. В деревьях классификации мы используем кросс-энтропию и Gini индекс. В деревьях регрессии мы минимизируем сумму квадратичной ошибки между предсказательной переменной целевых значений точек, попадающих в эту область, и той, которую мы присваиваем ей.
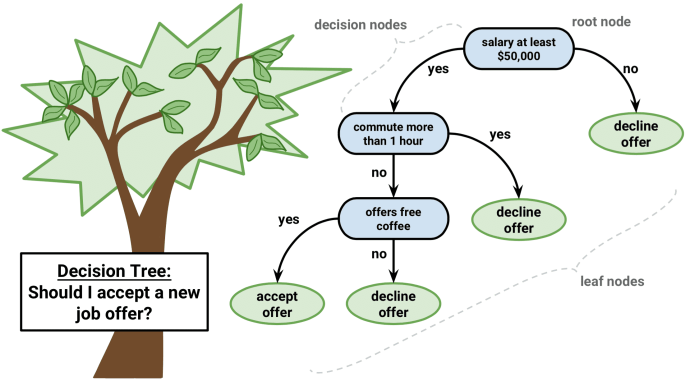
Мы делаем эту процедуру рекурсивно для каждого узла и заканчиваем, когда мы отвечаем критериям остановки. Они могут варьироваться от минимального количества листьев в узле до высоты дерева. Отдельные деревья используются очень редко, но по составу со многими другими они создают очень эффективные алгоритмы, такие как случайное увеличение леса или градиента.
Метод k-средних
Иногда, вам ничего не известно о свойствах, и ваша цель - назначать свойства в соответствии с особенностями объектов. Это называется задачей кластеризации.
Предположим, вы хотите разделить все объекты данных на k кластеров. Вам нужно выбрать случайные k точек из ваших данных и назвать их центрами кластеров. Кластеры других объектов определяются ближайшим центром кластера. Затем центры кластеров преобразуются и процесс повторяется до сходимости.

Это самая четкая техника кластеризации, но она по-прежнему имеет некоторые недостатки. Прежде всего, вы должны знать ряд кластеров, которые мы не можем знать. Во-вторых, результат зависит от точек, случайно выбранных в начале, и алгоритм не гарантирует, что мы достигнем глобального минимума функционала.
Существует ряд методов кластеризации с различными преимуществами и недостатками, которые вы могли бы изучить в рекомендуемом чтении.
Анализ основных компонентов
Вы когда-нибудь готовились к трудному экзамену ночью или даже утром, прямо перед тем, как он начнется? Невозможно запомнить всю необходимую информацию, но вы хотите максимизировать информацию, которую вы можете запомнить за доступное время; например, сначала изучить теоремы, которые встречаются во многих экзаменах и т. д.
Анализ основных компонентов основан на этой же идее. Этот алгоритм обеспечивает уменьшение размерности. Иногда у вас есть широкий спектр функций, которые, вероятно, сильно коррелированы между собой, а модели могут легко перегружать огромные объемы данных. Затем вы можете применить данный алгоритм.
Удивительно, но эти векторы являются собственными векторами корреляционной матрицы признаков из набора данных.
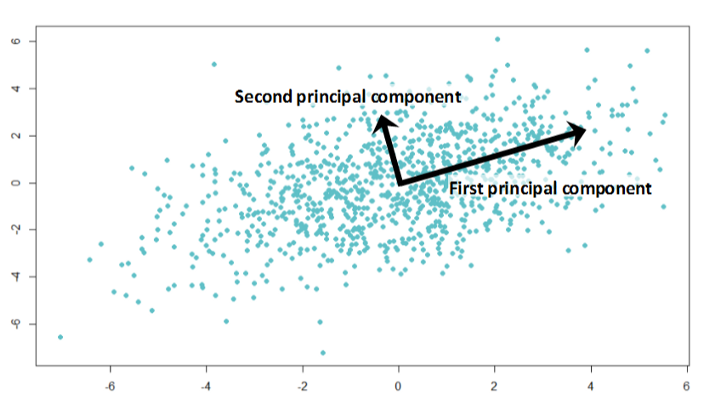
Теперь алгоритм понятен:
- Мы вычисляем корреляционную матрицу столбцов признаков и находим собственные векторы этой матрицы.
- Мы берем эти многомерные вектора и вычисляем проекцию всех признаков на них.
Новые функции - координаты от проекции, а их число зависит от количества собственных векторов, на которых вы рассчитываете проекцию.
Нейронные сети
Я уже упоминал о нейронных сетях, когда мы говорили о логистической регрессии. Существует множество различных архитектур, которые ценны в конкретных задачах. Чаще всего это диапазон слоев или компонентов с линейными соединениями между ними и следующими нелинейностями.
Если вы работаете с изображениями, сверточные глубокие нейронные сети показывают отличные результаты. Нелинейности представлены сверточными и объединяющими слоями, способными фиксировать характерные особенности изображений.

Для работы с текстами и последовательностями вам лучше выбрать рекуррентные нейронные сети (англ. Recurrent neural network ; RNN ). RNN содержат модули долгой краткосрочной памяти или управляемых рекуррентных нейронов и могут работать с данными, для которых мы заранее знаем размер. Одним из наиболее известных приложений RNN является машинный перевод.
Заключение
Я надеюсь, что вы теперь понимаете общие представления о наиболее используемых алгоритмах машинного обучения и имеете интуицию в том, как выбрать один из них для вашей конкретной задачи. Чтобы облегчить вам работу, я подготовил структурированный обзор их основных функций:
- Линейная регрессия и линейный классификатор : несмотря на кажущуюся простоту, они очень полезны при огромном количестве функций, где лучшие алгоритмы страдают от переобучения.
- Логистическая регрессия : простейший нелинейный классификатор с линейной комбинацией параметров и нелинейной функцией (сигмоид) для двоичной классификации.
- Деревья принятия решений : часто подобны процессу принятия решений людьми и легко интерпретируются, но чаще всего используются в таких композициях, как случайный рост леса или градиента.
- Метод k-средних : более примитивен, но очень простой в понимании алгоритм, который может быть идеальным в качестве основы во множестве задач.
- Анализ основных компонентов : отличный выбор для уменьшения размерности вашего пространства с минимальной потерей информации.
- Нейронные сети : новая эра алгоритмов машинного обучения, которые могут применяться для многих задач, но их обучение требует огромной вычислительной сложности.
Рекомендуемая литература
- Обзор методов кластеризации
- Полный учебник по регрессии хребтов и лассо в Python
- Youtube канал об AI для начинающих с отличными руководствами и примерами
Статья написана: Daniil Korbut | Октябрь 27, 2017г.
