- 1. Lernen mit einem Lehrer
- 2. Lernen ohne Lehrer
- 3. Training mit teilweiser Einbeziehung des Lehrers
- 4. Lernen durch Verstärkung
- 5. Die am häufigsten verwendeten Algorithmen für maschinelles Lernen
- 6. Lineare Regression und linearer Klassifikator
- 7. Logistische Regression
- 8. Entscheidungsbäume
- 9. k-means-Methode
- 10. Hauptkomponentenanalyse
- 11. Neuronale Netze
- 12. Fazit
- 13. Literatur-Empfehlungen
Viele Artikel über Algorithmen für maschinelles Lernen bieten großartige Definitionen – aber sie machen es nicht einfach, den Algorithmus auszuwählen, den Sie verwenden sollten. Lesen Sie diesen Artikel!
Als ich meine Data-Science-Reise begann, stand ich oft vor dem Problem, den am besten geeigneten Algorithmus für meine spezielle Aufgabe auszuwählen. Wenn Sie wie ich einen Artikel über maschinelle Lernalgorithmen öffnen, sehen Sie Hunderte von detaillierten Beschreibungen. Das Paradoxe ist, dass es die Auswahl nicht einfacher macht.
In diesem Artikel für Statsbot werde ich versuchen, die Grundkonzepte zu erklären und etwas Intuition für die Verwendung verschiedener Arten von maschinellen Lernalgorithmen für verschiedene Aufgaben zu vermitteln. Am Ende des Artikels finden Sie eine strukturierte Übersicht über die Hauptmerkmale der beschriebenen Algorithmen.
Zunächst sind vier Arten von Machine-Learning-Aufgaben zu unterscheiden:
- Überwachtes Lernen
- Lernen ohne Lehrer
- [Teilweise beteiligtes Lernen]
- Verstärkungstraining
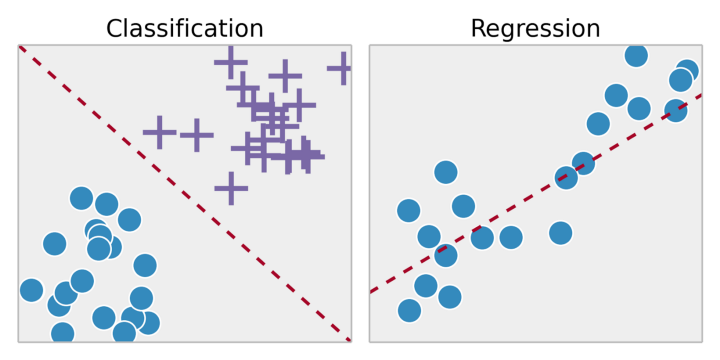
Lernen mit einem Lehrer
Überwachtes Lernen ist die Aufgabe, ein System auf einem Trainingsdatensatz zu trainieren. Durch Anpassen der Trainingsergebnisse an den Trainingsdatensatz wollen wir die optimalsten Modellparameter für die Vorhersage möglicher Reaktionen auf andere Objekte (Testdatensätze) finden. Wenn die Menge der möglichen Antworten eine reelle Zahl ist, handelt es sich um ein Regressionsproblem. Wenn die Menge der möglichen Antworten eine begrenzte Anzahl von Werten hat, wobei diese Werte ungeordnet sind, dann ist dies ein Klassifizierungsproblem.
Lernen ohne Lehrer
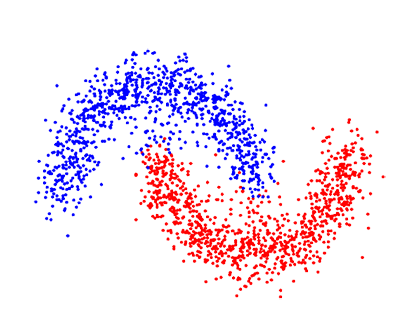
Beim unüberwachten Lernen haben wir weniger Informationen über Objekte. Insbesondere weist der Trainingsdatensatz keine gekennzeichneten Daten auf, die zu einer bestimmten Klasse vordefinierter Daten gehören. Was ist jetzt unser Ziel? Es ist möglich, eine gewisse Ähnlichkeit zwischen Gruppen von Objekten zu beobachten und sie in die entsprechenden Cluster aufzunehmen. Einige Objekte können sich sehr von allen Clustern unterscheiden, und daher nehmen wir an, dass diese Objekte Anomalien sind.
Training mit teilweiser Einbeziehung des Lehrers
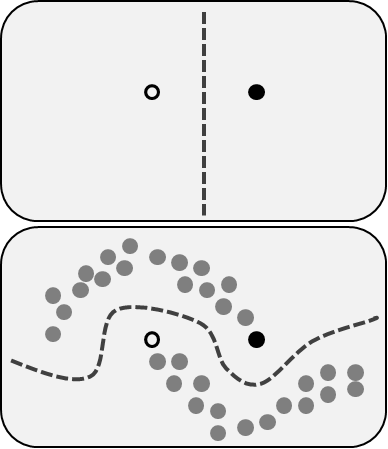
Teilweise überwachtes Lernen beinhaltet beide Probleme, die wir zuvor beschrieben haben: Sie verwenden gekennzeichnete, vordefinierte und nicht vordefinierte, nicht gekennzeichnete Daten. Dies ist eine großartige Gelegenheit für diejenigen, die ihre Daten nicht neu definieren und kennzeichnen können. Diese Methode ermöglicht eine deutliche Steigerung der Genauigkeit, da wir undefinierte Daten im Trainingsdatensatz mit einer kleinen Menge an gekennzeichneten vordefinierten Daten verwenden können.
Lernen durch Verstärkung
Reinforcement Learning ist anders als alle unsere vorherigen Aufgaben, da wir hier weder vordefinierte beschriftete Daten noch unbeschriftete Datensätze haben. Reinforcement Learning ist ein Bereich des maschinellen Lernens, der sich damit befasst, wie Softwareagenten in einer bestimmten Umgebung Maßnahmen ergreifen sollten, um eine gewisse Vorstellung von kumulativer Belohnung zu maximieren.
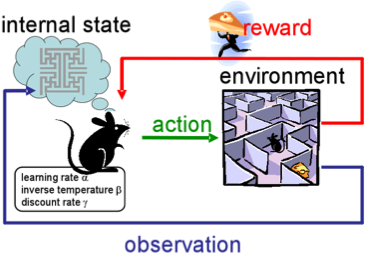
Stell dir vor, du bist ein Roboter an einem fremden Ort. Sie können Aktionen ausführen und dafür Belohnungen aus der Umgebung erhalten. Nach jeder Aktion wird Ihr Verhalten komplexer und intelligenter, sodass Sie sich selbst trainieren, sich bei jedem Schritt so effizient wie möglich zu verhalten. In der Biologie nennt man das Anpassung an die natürliche Umgebung.
Die am häufigsten verwendeten Algorithmen für maschinelles Lernen
Nachdem wir nun mit den Arten von Problemen beim maschinellen Lernen vertraut sind, schauen wir uns die beliebtesten Algorithmen mit ihrer Anwendung im wirklichen Leben an.
Lineare Regression und linearer Klassifikator
Dies sind wahrscheinlich die einfachsten Algorithmen für maschinelles Lernen. Sie haben Merkmale x1, ... xn Objekte (Matrix A) und Labels (Vektor b). Ihr Ziel ist es, die optimalsten Gewichte w1, ... wn und Bias für diese Merkmale gemäß einer Verlustfunktion zu finden; B. RMS-Fehler oder mittlerer absoluter Fehler für ein Regressionsproblem. Beim Root Mean Square Error gibt es eine mathematische Gleichung aus der Methode der kleinsten Quadrate:
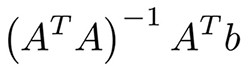
In der Praxis ist es einfacher, es mit Gradientenabstieg zu optimieren, was viel recheneffizienter ist. Trotz der Einfachheit dieses Algorithmus funktioniert er sehr gut, wenn Sie Tausende von Funktionen haben; zum Beispiel eine Reihe von Wörtern oder N-Grammen in der Textanalyse. Komplexere Algorithmen leiden eher unter der Neuzuweisung vieler Merkmale als unter riesigen Datensätzen, während die lineare Regression eine anständige Qualität bietet.

Um eine Überanpassung zu verhindern, verwenden wir häufig Regularisierungsmethoden wie Lasso und Kamm. Die Idee ist, die Summe der Moduli der Gewichte bzw. die Summe der Quadrate der Gewichte zu unserer Verlustfunktion zu addieren. Lesen Sie das große Tutorial zu diesen Algorithmen am Ende des Artikels.
Logistische Regression
Verwechseln Sie diese Klassifizierungsalgorithmen nicht mit Regressionsmethoden aufgrund der Verwendung von „regression“ im Namen. Die logistische Regression führt eine binäre Klassifizierung durch, sodass die beschrifteten Ausgaben binär sind. Lassen Sie uns P(y = 1 | x) als die bedingte Wahrscheinlichkeit definieren, dass die Ausgabe y 1 ist, vorausgesetzt, dass die Eingabevektorfunktion x gegeben ist. Die w-Koeffizienten sind die Gewichtungen, die das Modell lernen möchte.
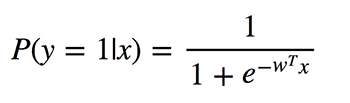
Da dieser Algorithmus die Wahrscheinlichkeit der Zugehörigkeit zu jeder Klasse berechnet, müssen Sie berücksichtigen, wie stark die Wahrscheinlichkeit von 0 oder 1 abweicht, und sie über alle Objekte mitteln, wie Sie es bei der linearen Regression getan haben. Eine solche Verlustfunktion ist der Durchschnitt der Kreuzentropie:
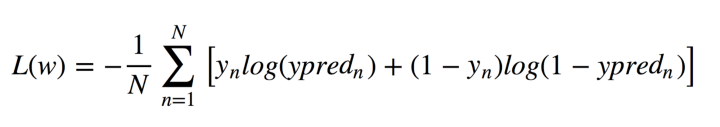
Keine Panik! Ich werde es dir leicht machen. Lassen Sie y die richtigen Antworten haben: 0 oder 1, y_pred sind die vorhergesagten Antworten. Wenn y 0 ist, dann ist der erste Term in der Summe 0, und der zweite Term ist kleiner, als wir gemäß den Eigenschaften des Logarithmus y_pred auf 0 vorhergesagt haben. Ähnlich in dem Fall, in dem y gleich 1 ist.
Was ist gut an der logistischen Regression? Es nimmt eine lineare Kombination von Merkmalen und wendet eine nichtlineare (Sigmoid-)Funktion darauf an, also ist es eine sehr kleine neuronale Netzwerkinstanz!
Entscheidungsbäume
Ein weiterer beliebter und leicht verständlicher Algorithmus sind Entscheidungsbäume. Ihre Grafiken helfen Ihnen zu verstehen, was Sie denken, und ihre Engine erfordert einen systematischen, dokumentierten Denkprozess.
Die Idee dieses Algorithmus ist recht einfach. An jedem Knoten wählen wir die beste Option aus allen Merkmalen und allen möglichen Teilungspunkten. Jede Option wird so gewählt, dass einige Funktionen maximiert werden. In Klassifikationsbäumen verwenden wir Kreuzentropie und den Gini-Index. In Regressionsbäumen minimieren wir die Summe des quadratischen Fehlers zwischen der Prädiktorvariablen der Zielwerte der Punkte, die in diese Region fallen, und der, die wir ihr zuweisen.
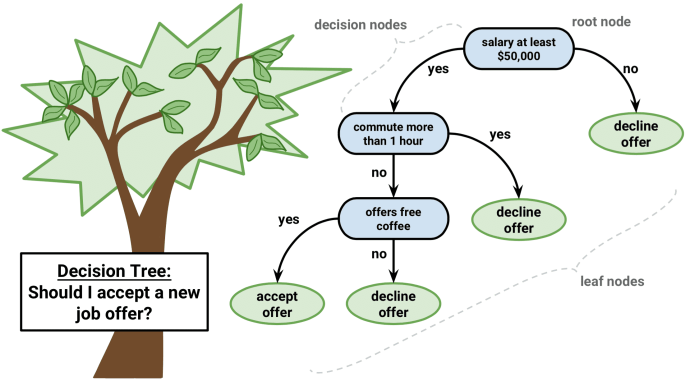
Wir führen dieses Verfahren rekursiv für jeden Knoten durch und enden, wenn wir die Stoppkriterien erfüllen. Sie können von der Mindestanzahl an Blättern pro Knoten bis zur Baumhöhe reichen. Einzelne Bäume werden sehr selten verwendet, aber in Kombination mit vielen anderen erzeugen sie sehr effiziente Algorithmen, wie z. B. Random Forest oder Gradient Growth.
k-means-Methode
Manchmal wissen Sie nichts über Eigenschaften, und Ihr Ziel ist es, Eigenschaften gemäß den Merkmalen der Objekte zuzuweisen. Dies wird als Clustering-Problem bezeichnet.
Angenommen, Sie möchten alle Datenobjekte in k Cluster aufteilen. Sie müssen zufällige k Punkte aus Ihren Daten auswählen und sie Clusterzentren nennen. Cluster anderer Objekte werden durch das nächste Clusterzentrum definiert. Dann werden die Clusterzentren transformiert und der Prozess wird bis zur Konvergenz wiederholt.

Dies ist die klarste Clustering-Technik, hat aber noch einige Nachteile. Zunächst müssen Sie eine Reihe von Clustern kennen, die wir nicht kennen können. Zweitens hängt das Ergebnis von den zu Beginn zufällig ausgewählten Punkten ab, und der Algorithmus garantiert nicht, dass wir das globale Minimum der Funktion erreichen.
Es gibt eine Reihe von Clustering-Methoden mit verschiedenen Vor- und Nachteilen, die Sie in der empfohlenen Lektüre untersuchen können.
Hauptkomponentenanalyse
Haben Sie schon einmal nachts oder sogar morgens kurz vor Beginn für eine schwierige Prüfung gelernt? Es ist nicht möglich, sich alle benötigten Informationen zu merken, aber Sie möchten die Informationen, an die Sie sich erinnern können, in der verfügbaren Zeit maximieren; Studieren Sie zum Beispiel zuerst die Sätze, die in vielen Prüfungen vorkommen usw.
Die Hauptkomponentenanalyse basiert auf der gleichen Idee. Dieser Algorithmus stellt eine Dimensionsreduktion bereit. Manchmal verfügen Sie über eine Vielzahl von Features, die wahrscheinlich stark korrelieren, und Modelle können riesige Datenmengen leicht überfordern. Dann können Sie diesen Algorithmus anwenden.
Überraschenderweise sind diese Vektoren Eigenvektoren der Merkmalskorrelationsmatrix aus dem Datensatz.
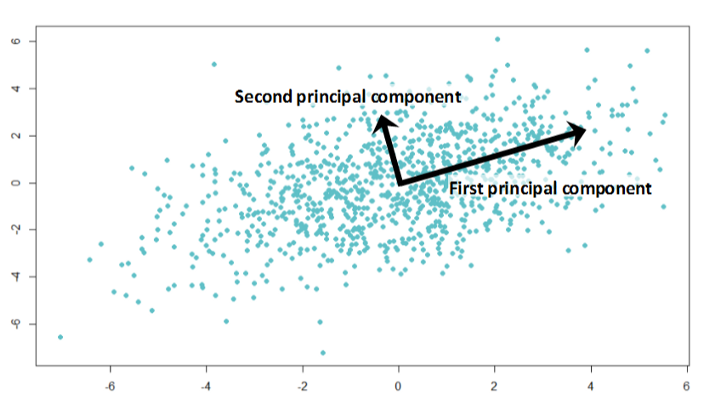
Jetzt ist der Algorithmus klar:
- Wir berechnen die Korrelationsmatrix von Merkmalsspalten und finden die Eigenvektoren dieser Matrix.
- Wir nehmen diese mehrdimensionalen Vektoren und berechnen die Projektion aller Merkmale darauf.
Die neuen Funktionen sind Koordinaten aus der Projektion, und ihre Anzahl hängt von der Anzahl der Eigenvektoren ab, auf denen Sie die Projektion berechnen.
Neuronale Netze
Ich habe bereits neuronale Netze erwähnt, als wir über logistische Regression gesprochen haben. Es gibt viele verschiedene Architekturen, die in spezifischen Anwendungen wertvoll sind. Meistens handelt es sich um eine Reihe von Schichten oder Komponenten mit linearen Verbindungen zwischen ihnen und den folgenden Nichtlinearitäten.
Wenn Sie mit Bildern arbeiten, sind Convolutional Deep Neural Networks großartig. Nichtlinearitäten werden durch Faltungs- und Pooling-Schichten dargestellt, die in der Lage sind, die charakteristischen Merkmale von Bildern zu erfassen.

Um mit Texten und Sequenzen zu arbeiten, wählen Sie besser rekurrente neuronale Netze (engl. Recurrent neural network ; RNN ). RNNs enthalten Module des langen Kurzzeitgedächtnisses oder kontrollierte wiederkehrende Neuronen und können mit Daten arbeiten, deren Größe wir im Voraus kennen. Eine der bekanntesten Anwendungen von RNN ist die maschinelle Übersetzung.
Fazit
Ich hoffe, dass Sie jetzt die allgemeinen Konzepte der am häufigsten verwendeten maschinellen Lernalgorithmen verstehen und eine Intuition haben, wie Sie einen von ihnen für Ihr spezielles Problem auswählen können. Um es Ihnen einfacher zu machen, habe ich eine strukturierte Übersicht über ihre wichtigsten Funktionen erstellt:
- Lineare Regression und linearer Klassifikator : Trotz ihrer offensichtlichen Einfachheit sind sie sehr nützlich für eine große Anzahl von Funktionen, bei denen die besten Algorithmen unter Überanpassung leiden.
- Logistische Regression : der einfachste nichtlineare Klassifikator mit einer linearen Kombination von Parametern und einer nichtlinearen Funktion (Sigmoid) für die binäre Klassifizierung.
- Entscheidungsbäume : Oft ähnlich der menschlichen Entscheidungsfindung und leicht zu interpretieren, aber am häufigsten in Kompositionen wie Random Forest oder Gradient Growth verwendet.
- K-Means : Ein primitiverer, aber sehr einfach zu verstehender Algorithmus, der als Basis für viele Probleme ideal sein kann.
- Hauptkomponentenanalyse : Eine ausgezeichnete Wahl, um die Dimensionalität Ihres Raums mit minimalem Informationsverlust zu reduzieren.
- Neuronale Netze : eine neue Ära maschineller Lernalgorithmen, die auf viele Probleme angewendet werden können, aber ihr Training erfordert eine enorme Rechenkomplexität.
Literatur-Empfehlungen
- Übersicht über Clustering-Methoden
- Das vollständige Tutorial zur Ridge- und Lasso-Regression in Python
- Youtube-Kanal über KI für Anfänger mit großartigen Tutorials und Beispielen
Artikel geschrieben von: Daniil Korbut | 27. Oktober 2017
